Разработан новый "умный" контроллер памяти с поддержкой DMA
- Информация о материале
- Опубликовано: 11.10.2014, 01:08
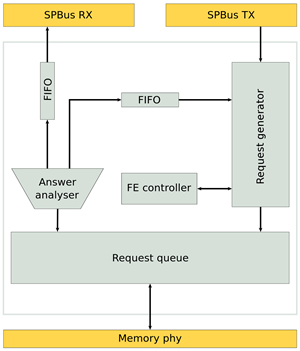 |
Общая схема контроллера памяти. Фото: maltsystem.com |
Разработана и протестирована новая версия "умного" контроллера памяти. Теперь контроллер поддерживает блочные передачи данных – механизм, позволяющий копировать данные из одной области памяти в другую без участия процессорных ядер, обычно называется DMA. Использование данного механизма позволяет в несколько раз увеличить производительность в задачах с интенсивным обменом данными. В новом контроллере реализован базовый набор "настоящих" атомарных операций, например поддерживается атомарный инкремент.
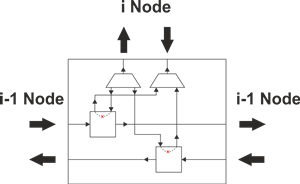
Новый контроллер памяти, так же как и его предыдущая версия, поддерживает механизм FE-битов. Данный механизм позволяет осуществлять синхронизацию доступа к памяти из различных потоков. В частности, контроллер позволяет приостанавливать выполнение потока в случае, если запрашиваемые данные ещё не получены, и практически мгновенно возобновлять его выполнение сразу после предоставления этих данных другим потоком.
Все перечисленные выше механизмы реализованы на аппаратном уровне, что обеспечивает максимальное быстродействие и энергоэффективность.